AI Healthcare Analytics: Use Cases, Architecture, and What Actually Works

Slava Khristich



Vlad Nazarov

| Key Takeaways: ✅ 71% of US hospitals deploy predictive AI with their EHR, but only 44% have evaluated those models for bias, creating significant clinical and compliance risk. ✅ The highest-ROI analytics use cases are revenue cycle and clinical documentation in the short term, and readmission reduction and sepsis detection at a larger scale. ✅ A HIPAA-compliant analytics data pipeline requires de-identification standards, audit logging for model inference, and cloud provider HIPAA-eligible services. ✅ Models trained on vendor datasets may perform significantly worse on your patient population. ✅ Demographic parity testing and subgroup analysis are required before production deployment. ✅ The build-vs-buy decision depends on EHR environment complexity, data portability requirements, and whether analytics is a core product or an administrative function. |
In this article, we explain what AI healthcare analytics actually means for hospitals and digital health teams: how predictive models turn clinical, operational, and financial data into risk scores, alerts, and decision-support outputs. You’ll see where analytics can create value fastest, including revenue cycle, documentation quality, scheduling, care gap closure, readmission risk, and sepsis detection.
The article also looks at the harder part: what has to happen before an analytics model belongs in production. That includes EHR data extraction, model-ready datasets, HIPAA-aware cloud infrastructure, audit logging, bias testing, subgroup validation, drift monitoring, and the build-vs-buy choice for health systems with different EHR environments and data ownership needs.
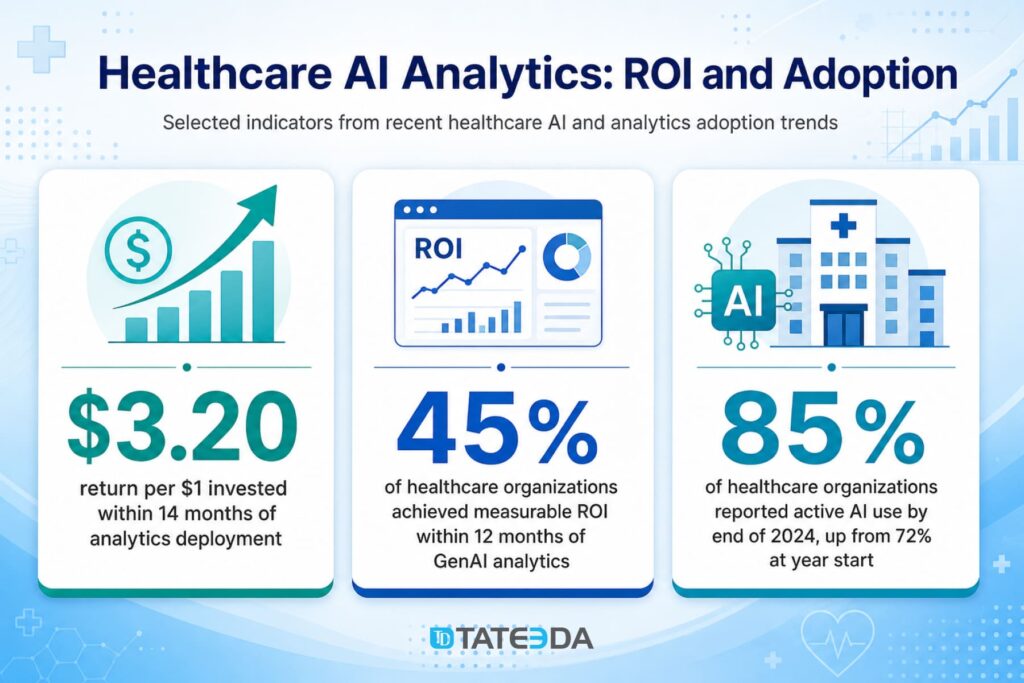
AI healthcare analytics refers to machine learning and data science systems that analyze clinical, operational, and financial data to surface predictions, risk scores, and decision support outputs that improve patient outcomes and reduce operating costs. Seventy-one percent of US hospitals now run predictive artificial intelligence integrated with their EHR systems. Fewer than half have ever evaluated those models for bias.

If you require technical assistance in developing a healthcare analytics application, please contact our AI software experts for individualized project consultation!
That gap is not a technology problem. It is a governance problem. And it is one of the reasons a health system CTO asking “should we deploy AI analytics?” needs a more nuanced answer than the market research reports provide.
This guide covers what AI healthcare analytics actually is, where the return on investment is clearest, what a HIPAA-compliant data pipeline requires, what clinical validation looks like before a risk model goes into production, and how to frame the build-vs-buy decision for your organization’s size, EHR environment, and use case complexity.
Why TATEEDA is worth listening to on AI-aided healthcare analytics
TATEEDA has been building healthcare software since 2013. Not AI commentary — actual product work for healthcare, pharma, and biotech organizations. Patient portals, medical staffing platforms, payment systems, EDC environments, remote monitoring apps, and lab-device software. The kind of work that teaches you what AI-aided analytics actually depends on before it becomes useful: clean data flow, connected systems, compliant architecture, and software that fits how clinical teams operate day to day.
That background shapes how we talk about this subject. The question is never “isn’t AI exciting?” It’s about what data you have, how trustworthy it is, where it moves, who acts on the output, and what actually changes after deployment. That’s a more honest place to write from.
Some of the work behind that perspective:
- A healthcare staffing platform that grew past 4,000 daily users, with time-tracking automation and big-data analysis built into daily operations
- A patient payment portal that cut unsuccessful payment attempts by 30% and reduced transaction processing time by half
- Visiontree EDC work running at dozens of new forms monthly, plus 40 to 50 updates per month — structured healthcare data capture at real scale
- SCRx process improvements that reduced manual work fivefold, a solid example of operational data and workflow improvement inside a regulated environment
- Remote heart-monitoring and lab-device projects built around live ECG access and device-to-software data exchange — exactly the technical ground healthcare analytics depends on before any model starts producing insight.
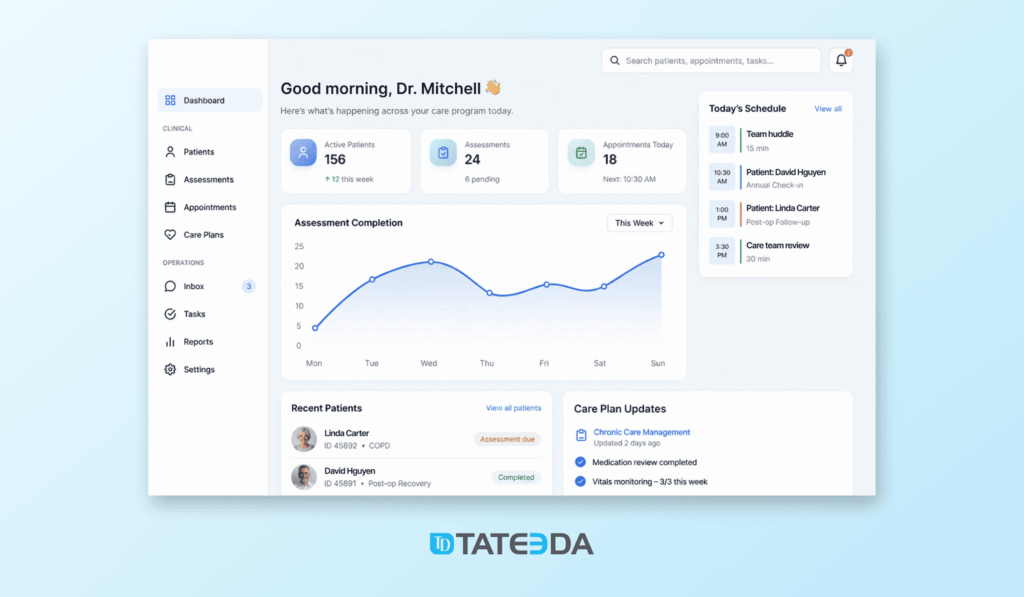
Table of Contents
What Is AI Healthcare Analytics?
AI healthcare analytics is the application of machine learning (ML), natural language processing (NLP), and statistical modeling to clinical, operational, and financial data to generate actionable insights. Unlike AI agents that execute tasks autonomously or AI chatbots that handle conversational patient interactions, analytics AI analyzes data to answer the question: what is likely to happen, and what should we do about it?
The seven primary use cases where analytics AI is deployed in US health systems today:
- Readmission risk prediction: identifying patients at high risk of 30-day readmission before discharge
- Sepsis and deterioration early warning: detecting physiological deterioration before clinical staff identify it manually
- Revenue cycle analytics and denial prediction: predicting likely claim denials before submission
- Scheduling and capacity optimization: matching staffing and OR utilization to predicted patient volumes
- Population health management: stratifying chronic disease panels for proactive care gap closure
- Clinical documentation quality and coding accuracy: flagging under-coded encounters for coder review
- Drug diversion and safety event detection: identifying anomalous controlled substance dispensing patterns.
These use cases range from pure operational efficiency (scheduling, coding) to direct clinical safety (sepsis detection, deterioration alerting). The data infrastructure, HIPAA requirements, and validation requirements differ significantly across that spectrum.
How Analytics AI Fits the Healthcare AI Cluster
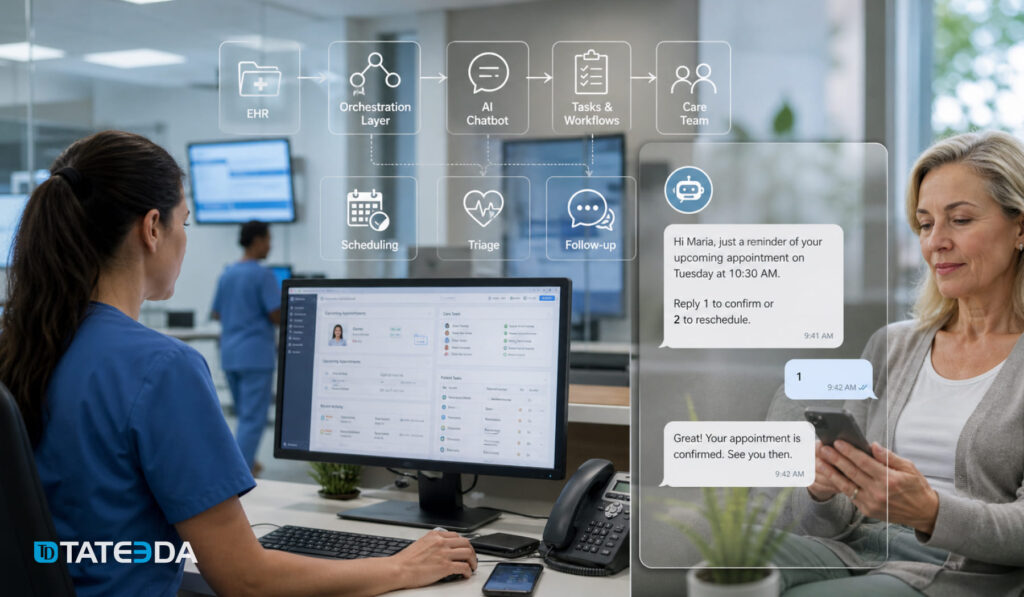
Analytics AI generates predictions and risk scores. AI agents in healthcare act on those predictions, executing downstream workflows like prior authorization or care coordination messaging. AI chatbots in healthcare handle the conversational layer, routing patients and answering questions. All three work together in a complete system, and none substitutes for the others.
| System Type | What It Does | Primary Use Case |
|---|---|---|
| Analytics AI | Analyzes data, generates predictions and risk scores | Analyzes data, generates predictions, and risk scores |
| Agentic AI | Takes autonomous action on workflow tasks | Readmission risk, sepsis alerts, and denial prediction |
| AI Chatbots | Handles conversational patient interactions | Prior auth, care coordination, and documentation |
AI Healthcare Analytics Use Cases: Where the ROI Is
Readmission and Sepsis Prediction
The Centers for Medicare and Medicaid Services (CMS) Hospital Readmissions Reduction Program penalizes hospitals financially for excess 30-day readmissions for heart failure, pneumonia, COPD, and hip/knee replacement. A readmission prediction model that correctly identifies high-risk patients before discharge, triggering enhanced discharge planning and post-acute follow-up, can directly reduce CMS penalties and improve care coordination outcomes.
Sepsis detection is a different problem with different infrastructure requirements. Sepsis can progress from early warning signs to organ failure in three to four hours. A model that scores patient deterioration risk once per day, or even every six hours, is not clinically useful. Sepsis detection requires near-real-time inference, and that has direct implications for data pipeline architecture covered in the next section.
Revenue Cycle and Denial Analytics
Claims denial rates average 5–10% across US health systems, and rework costs for denied claims run between $25 and $118 per denial, depending on complexity. AI denial prediction models that flag likely denials before submission, allowing staff to attach missing documentation or reroute to a different payer pathway, are showing 15–30% denial rate reductions in early production deployments.
Scheduling optimization is lower-profile but high-impact for systems where OR utilization inefficiency and no-show rates create significant lost revenue. Predictive no-show models can trigger proactive outreach workflows, and capacity optimization models can reduce overtime labor costs in predictable surge periods.
Ready to evaluate which analytics use cases fit your health system’s data environment?
Scope a сustom assessment for individualized project consultation!
Population Health and Care Gap Closure
Risk stratification for chronic disease management, identifying diabetic patients overdue for A1C testing or hypertensive patients without recent medication reconciliation, is a core function of population health management programs operating under value-based care contracts. Analytics AI converts raw EHR data into actionable care gap lists that care coordinators can work against.
In organizations that have deployed both analytics and agentic AI systems, the analytics layer generates the prioritized patient list and the agent layer executes the outreach, referral, or documentation follow-up. The two systems are complementary, not interchangeable.
The Data Pipeline: What HIPAA-Compliant Analytics Architecture Actually Requires
EHR Data Extraction and Model-Ready Datasets
The phrase “we can pull data from the EHR” covers a wide range of very different technical realities. There is a significant difference between raw EHR data and the structured, normalized, deduplicated, and enriched datasets that ML models can actually train on.
The three primary extraction patterns used in production healthcare analytics pipelines:
- 1FHIR Bulk Data API: the HL7 Fast Healthcare Interoperability Resources (FHIR) R4 Bulk Export API provides structured clinical data in NDJSON format. Epic and Oracle Health both support FHIR Bulk Data. This is the cleanest extraction path for vitals, labs, medications, and diagnoses.
- 2CCDA document parsing with NLP: Consolidated CDA documents contain rich clinical note data not available in structured FHIR resources. Extracting problem lists, medication histories, and clinical impressions from unstructured text requires NLP pipelines, and pipeline quality directly affects model performance.
- 3HL7 v2 ADT feeds: Health Level Seven version 2 Admit/Discharge/Transfer event feeds provide real-time patient event streams. For use cases requiring near-real-time scoring, including sepsis detection, ADT feeds are the source data. They are also the messiest to work with, requiring significant normalization before feeding a model.
A health system’s analytics team often discovers the gap between raw EHR data and model-ready datasets only after starting the first build. Three to six months of data engineering work precede meaningful model development in most first-time implementations.
Real-World Example: The Real-Time vs. Batch Mistake
The analytics team at a regional multi-hospital system designed their AI-powered sepsis early warning system with batch scoring on six-hour update cycles. After go-live, they discovered the clinical reality: sepsis can progress to organ failure in three to four hours, making six-hour-old risk scores nearly useless at the bedside.
They rebuilt the pipeline using streaming HL7 v2 ADT and lab result events, reducing scoring latency to under four minutes. The rebuild cost three months of additional development. The lesson: real-time vs. batch architecture must be driven by clinical use case requirements, not infrastructure convenience.
HIPAA Requirements for Analytics Data Environments
Running ML workloads on clinical data requires careful navigation of what the Health Insurance Portability and Accountability Act (HIPAA) Privacy Rule and Security Rule require. A HIPAA-compliant analytics pipeline includes:
- De-identification standard: Expert Determination (statistician certifies re-identification risk is very small) or Safe Harbor (removal of 18 specific identifier types). Most pipelines use a limited dataset under a Data Use Agreement (DUA), which retains dates and three-digit ZIP codes and is sufficient for most predictive modeling use cases.
- BAA on model training infrastructure: Training a predictive model on Protected Health Information (PHI) without a Business Associate Agreement (BAA) in place with your model hosting infrastructure is a HIPAA violation. AWS HealthLake and Azure Health Data Services operate under BAA. A standard developer AWS account does not.
- Audit logging for model inference: Every query against a clinical risk score must be logged with sufficient detail to support a HIPAA breach investigation: who accessed it, when, from what system, against which patient record.
- Data residency for cloud environments: HIPAA does not specify geography, but state law may, and health system security policies often do. Confirming that your analytics data lake and model training infrastructure run within appropriate geographic boundaries is part of the HIPAA-eligible service agreement review.
Real-Time vs. Batch Analytics: When Each Architecture Is Right
Real-time streaming analytics, built on event-driven infrastructure using tools like Apache Kafka and Apache Flink, is appropriate for use cases where scoring latency directly affects clinical decisions: sepsis and deterioration alerts, ED surge prediction, and real-time medication safety checks.
Batch scoring is the right choice for use cases where daily or weekly updates are clinically sufficient. Daily readmission risk stratification, weekly care gap list updates, and monthly revenue cycle anomaly reports are all batch use cases. Batch is significantly cheaper to operate and simpler to maintain than real-time streaming infrastructure.
The infrastructure cost implications are meaningful at scale. A real-time streaming pipeline for a 500-bed hospital might require dedicated stream processing infrastructure that adds $15,000 to $30,000 per year in cloud costs over an equivalent batch architecture. That is manageable for a sepsis detection use case with direct mortality impact; it is harder to justify for a scheduling optimization model where daily updates are sufficient.
TATEEDA’s custom AI analytics development for healthcare covers both pipeline architectures, with HIPAA-compliant infrastructure as the baseline for every build.

Bias, Validation, and What Health Systems Must Verify Before Deploying
The Validation Gap
The statistic that frames this problem: 71% of US hospitals have deployed predictive AI integrated with their EHR. Only 44% have evaluated their models for demographic bias, compared to 61% who evaluated for overall accuracy. Roughly one in four health systems is running a clinical risk model validated for mean performance but not for whether it performs equally across their patient population’s demographic subgroups.
This matters clinically because models trained on datasets that underrepresent certain populations will perform worse on those populations in production, precisely the patients where accurate risk identification often has the highest impact. A readmission prediction model that generates misleading scores for Medicaid patients does not just fail to help; it can worsen care disparities by directing attention and intervention resources toward the populations the model was trained on.
| Real-World Example: The Unvalidated Readmission Model A 400-bed regional health system deployed a vendor-provided 30-day readmission risk model in 2023. Twelve months after go-live, a clinical informatics review found that the model was flagging white Medicare patients at 78% recall while flagging Black Medicaid patients at only 52% recall. The model had been validated on the vendor’s training dataset, not on the health system’s actual patient population. The system paused the deployment and began a prospective validation study before restoring clinical access to the risk scores. The vendor’s training data disclosure, buried in the contract appendix, had not been reviewed by anyone on the clinical informatics team before deployment. |
What Clinical Validation Requires Before Deployment
Deploying a clinical AI risk model without adequate validation creates both patient safety risk and regulatory exposure. The Office of the National Coordinator for Health IT (ONC) published guidance in 2024 on hospital AI governance, identifying bias evaluation as a recommended practice. The Food and Drug Administration (FDA) has issued AI/ML Software as a Medical Device (SaMD) guidance for clinical decision support tools. The standard before deployment includes four components:
- Demographic parity testing: Does the model produce equally calibrated risk scores across race, age, sex, and insurance type? This is a minimum bar, not a comprehensive validation.
- Subgroup performance analysis: Precision and recall broken down by each patient subpopulation in your actual patient population. The subgroups in the vendor’s training dataset may not match yours.
- Prospective validation: Testing model performance against a prospective patient cohort on your data, not just the training data hold-out set. Prospective validation tells you whether the model will perform on the patients you actually have.
- External validation: Only 34% of FDA-cleared AI imaging products have been validated by multiple institutions. For clinical decision support models used at the bedside, single-institution validation is increasingly recognized as insufficient.
Post-Deployment Governance and Model Monitoring
A clinical AI model that performed well at deployment may degrade over time as patient populations shift, clinical workflows change, or EHR documentation patterns evolve. The governance structure required to catch this before it causes patient harm includes three elements:
- Performance monitoring and drift detection: Automated monitoring against a labeled holdout set updated with recent outcomes data. When performance metrics drop below a defined threshold, the model goes back for revalidation.
- Alert fatigue calibration: A sepsis alert that fires for 30% of patients, when true sepsis prevalence is 2%, is worse than no alert because it desensitizes clinical staff. Risk threshold calibration requires collaboration between data scientists and bedside clinicians.
- Explainability: SHAP (Shapley Additive Explanations) values can surface the features driving an individual patient’s risk score, “high risk driven by elevated lactate, tachycardia, and recent ICU transfer,” in a format that is actionable at the bedside.

| Clinical Deployment Warning Deploying an unvalidated risk model in a clinical workflow is not a temporary shortcut. A model that performs worse on a protected patient subgroup creates health disparities, potential regulatory exposure under ONC and CMS guidance, and malpractice liability if a missed high-risk patient outcome can be traced to a known model deficiency. Validate before you go live. |
Build vs. Buy: The Decision Framework for Health System Analytics
When Off-the-Shelf Analytics Platforms Work
Three categories of analytics platforms work well for specific health system profiles:
- Epic-native analytics: Healthy Planet, SlicerDicer, and Cosmos are best for health systems fully standardized on Epic. The advantage is tight EHR integration; the constraint is that the models are Epic’s, trained on Epic’s data, with limited customization for your patient population.
- Purpose-built multi-EHR platforms: Health Catalyst, Arcadia, and Innovaccer all provide HIPAA-compliant healthcare analytics platforms with pre-built EHR connectors and pre-trained models for common use cases. These work well for community hospitals deploying a single analytics use case without the resources to build a custom data infrastructure.
- Cloud-native health data platforms: AWS HealthLake and Azure Health Data Services provide FHIR-native HIPAA-eligible cloud infrastructure with pre-built analytics connectors, best for digital health companies that want to build on managed HIPAA-eligible services.
Vendor contracts warrant close review on two clauses before signing: data portability (can you export your data if you leave?) and model training data use (can the vendor use your patient data to train their next model version?).
When Custom Development Is the Right Choice
| Choose Off-the-Shelf When | Choose Custom When |
|---|---|
| ✅ Single EHR environment (Epic) ✅ Standard use cases (readmissions, care gaps ✅ Limited in-house data engineering ✅ Community hospital or single-site ✅ One-use-case pilot before broader rollout | ✅ Multi-EHR environment (Epic + athenahealth) ✅ Proprietary or specialty use cases ✅ You need to own training data and models ✅ Analytics is a core product, not a back-office ✅ State data residency requirements not met by SaaS |

| Real-World Example: The Build Decision A digital health company building a care management platform for value-based care contracts evaluated three analytics vendors before building their own. Each vendor offered “EHR integration,” but on evaluation, all three operated on nightly flat-file exports rather than FHIR APIs and could not handle their multi-EHR member population (some on Epic, others on athenahealth). All three required the company’s patient data to reside in the vendor’s cloud under a contract with no data portability clause. The company built a custom FHIR R4 data pipeline backed by AWS HealthLake. Time to production: six months. Total infrastructure cost: $180,000 in the first year, compared to the $420,000 in combined vendor licensing they had been quoted. More importantly, they own the models, the training data, and the pipeline. |
What to Look for in a Custom Analytics Development Partner
When custom healthcare software development is the right choice, the partner selection criteria differ from standard software development:
- HIPAA-compliant data pipeline experience by default: Engineers who have built production HIPAA analytics environments understand BAA scope, PHI segregation, audit logging, and HIPAA-eligible cloud service selection as part of their standard workflow.
- Demonstrated FHIR and HL7 EHR integration experience: Specifically with your EHR version and the FHIR resource types relevant to your use case. An engineer who has built Epic FHIR Bulk Data pipelines and one who has never worked with EHR APIs will produce very different outcomes.
- Model validation and clinical informatics capability: ML engineering and clinical informatics are different skill sets. A development partner who can build the model but not design or execute the validation study creates risk at the point where validated deployment is what separates a useful tool from a liability.
- FDA SaMD awareness: Clinical decision support tools that meet the FDA’s SaMD definition require a different development and validation process than administrative analytics. A partner unfamiliar with that distinction can deliver a product that cannot legally be deployed in the clinical context it was built for.
TATEEDA’s EHR and EMR integration services and healthcare IT consulting practices support both the scoping and the build phases of custom healthcare analytics implementations, with HIPAA compliance built into the pipeline architecture from day one.
FAQ: AI Healthcare Analytics
What is AI healthcare analytics?
AI healthcare analytics refers to machine learning and data science systems that analyze clinical, operational, and financial data to generate predictions, risk scores, and decision support outputs. Primary use cases include readmission risk stratification, sepsis early warning, revenue cycle optimization, scheduling and capacity planning, population health management, clinical documentation quality, and drug diversion detection.
What are the most valuable AI analytics use cases for health systems?
Revenue cycle analytics, clinical documentation improvement, and scheduling optimization generate the fastest measurable ROI, typically within six to twelve months. Readmission reduction and sepsis detection have a larger long-term impact but require longer validation timelines and more complex data infrastructure. CMS readmission penalties make readmission reduction a financial priority for most acute care hospitals.
How does a HIPAA-compliant analytics data pipeline work?
A HIPAA-compliant analytics pipeline includes: FHIR Bulk Data API or HL7 v2 feed extraction from the EHR; a transformation layer applying de-identification or limited dataset standards; a HIPAA-eligible cloud data lake (AWS HealthLake or Azure Health Data Services) under a Business Associate Agreement; model training and inference infrastructure within the same HIPAA-eligible boundary; audit logging for all data access and model inference; and access controls limiting PHI to authorized users and systems.
How long does it take to implement AI analytics in a health system?
A vendor platform deployment for a single use case typically takes three to six months, including configuration, data validation, and staff training. Custom pipeline development for a novel use case or multi-EHR environment typically takes six to twelve months from kickoff to production, with the first three to six months focused on data engineering before model development begins. Most health systems underestimate the data preparation phase.
What is the difference between AI healthcare analytics and agentic AI in healthcare?
Analytics AI analyzes data to generate predictions and risk scores. It answers the question: what is likely to happen? Agentic AI takes autonomous action on those predictions, executing tasks like prior authorization submission, care coordination outreach, or clinical documentation generation. The two systems are complementary. The role of agentic AI in healthcare covers the action layer in detail.
How do you evaluate a healthcare AI analytics model for bias?
Clinical bias evaluation requires, at a minimum, demographic parity testing across race, age, sex, and insurance type; subgroup-level precision and recall analysis; prospective validation on a patient cohort from your health system; and comparison of your patient population demographics against the model’s training data demographics. If the training data does not represent your population, the model’s aggregate accuracy metrics are not a reliable indicator of real-world performance.






